Lecture 6: Relaxation Labelling
We have already noted the problem of missing information in the image, which may be due to noise, or perhaps to occlusion. In the previous lecture, the contextual information was expressed in the prior assumption that contours are continuous. Later in the course, we will see examples that depend on higher levels of contextual knowledge. Relaxation labelling is a formal method of expressing low level contextual information, and applying it to complete the extraction of image features. It can be applied equally well to regions or edges. It is a well studied technique, and has been the subject of considerable research over the last twenty years.
Probabilistic relaxation formulation
In the normal formulation relaxation is stated as a labelling problem. For an image we may wish to label each pixel as belonging to an edge, or being part of a region. Hence we define:
{a1,a2, . . . an} a set of objects (eg pixels, line segments)
{l1,l2 . . . lm} a set of labels
For example, we would normally have pixels as the objects, and the labels could be 'edge' or 'not edge'. Associated with each ai is a set of measurements Xi, and also associated with each ai is the contextual information of the other objects, which will depend on the current labels. Ideally, we would like to assign each object one label, but this will not in general be possible, and so we will have, for each object a set of probabilities of each label:
|
{P(ai:l1),P(ai:l2),P(ai:l3) . . . P(ai:lm)} |
S |
(a:,lj) = 1 |
|
j |
where P(ai:lj) is the probability of the object ai having label lj given the measurements and contextual information. The contextual information is expressed by compatibility coefficients:
r([ai:lj], [ak:ll])
The value of r is a measure of how compatible it would be to label ai with lj and ak with ll. There will be one compatibility coefficient for each possible labelling of each pair of objects in the set. Relaxation is an iterative process. We start with some assumption of the probabilities, use that to calculate the contextual information, and then re-calculate the probabilities. We write Ps(aj:lk) for the sth iteration of the estimate of the probability that object aj has label lk. We define the total contextual support, from object aj, for the assignment of label ll to node ai as:
|
m |
||
|
qsj(ai:ll) = |
S |
r([ai:ll],[aj:lk]) Ps(aj:lk) |
|
k=1 |
summing this over all the objects gives the total support of the assignment of label ll to node ai:
|
n |
||
|
Qs(ai:ll) = |
S |
Cij qsj(ai:ll) |
|
j=1 |
The Cij coefficients weight the relative importance of node pairs in supplying each other a context. The iterative scheme is now defined as follows:
|
m |
|||
|
Ps+1(ai:ll) = Ps(ai:ll) ( Qs(ai:ll) / { |
S |
Ps(ai:lk) Qs(ai:lk) } ) |
(Eqn 1) |
|
k=1 |
The normalisation is necessary to ensure that the probabilities sum to 1. The algorithm that can obtained from this equation is justified largely by intuition. It is sometimes termed the non-linear relaxation scheme, and alternative schemes have been proposed.
Relaxation for Region based Segmentation
When using relaxation in region based segmentation we need to formulate the number and character of the regions that we are aiming to extract. This may be done automatically, for example by searching the image for uniform seed regions, or may be considered part of the prior knowledge. Let us suppose that we have four regions, and in the simplest case each is characterised by the mean intensity of the pixels. Each region is allocated a label.
We now need to make an initial estimate, for each pixel in the image, as to the probability of that pixel having each label. To do this in general, we need to calculate some measure that tells us how far the pixel is from the mean value that characterises each region. A simple measure is the absolute difference between the pixel intensity and the mean characterising the region.
d(aj,li) = |I(ai)-mi|
This then needs to be turned into a probability, which can be done by normalising the distances and subtracting from 1.
|
p1(aj:li) =1 - d(aj,li) / { |
S |
d(aj,li) } |
|
i |
We now need to specify what the compatibilities should be. Here it may be possible to use domain specific information. For example, if we know that in a given application one region never joins another, then the compatibility can be set to zero. In general though we cannot say more than pixels with the same label are highly compatible and those with different labels are less compatible. That is to say:
|
r([ai:lj], [ak:ll]) = |
1 if lj = ll |
|
= |
0 otherwise |
Lastly, we need to specify the area over which the relaxation takes place, and typically this will be the three by three area surrounding the pixel. Thus
|
Cij = |
1 if ai next to aj |
|
= |
0 otherwise |
Relaxation labelling for Edge detection
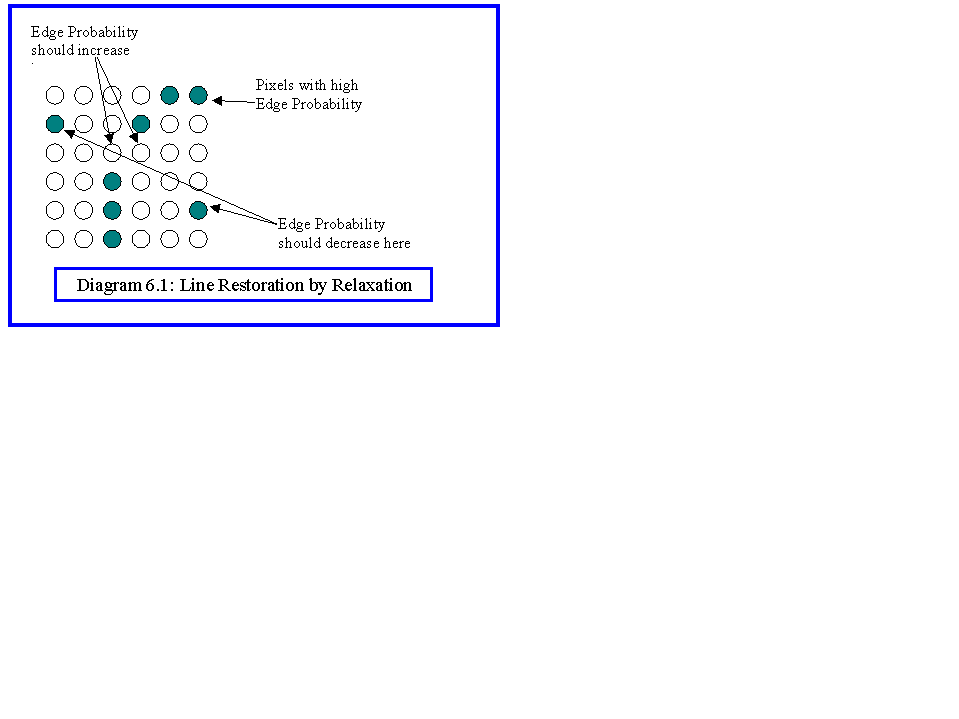
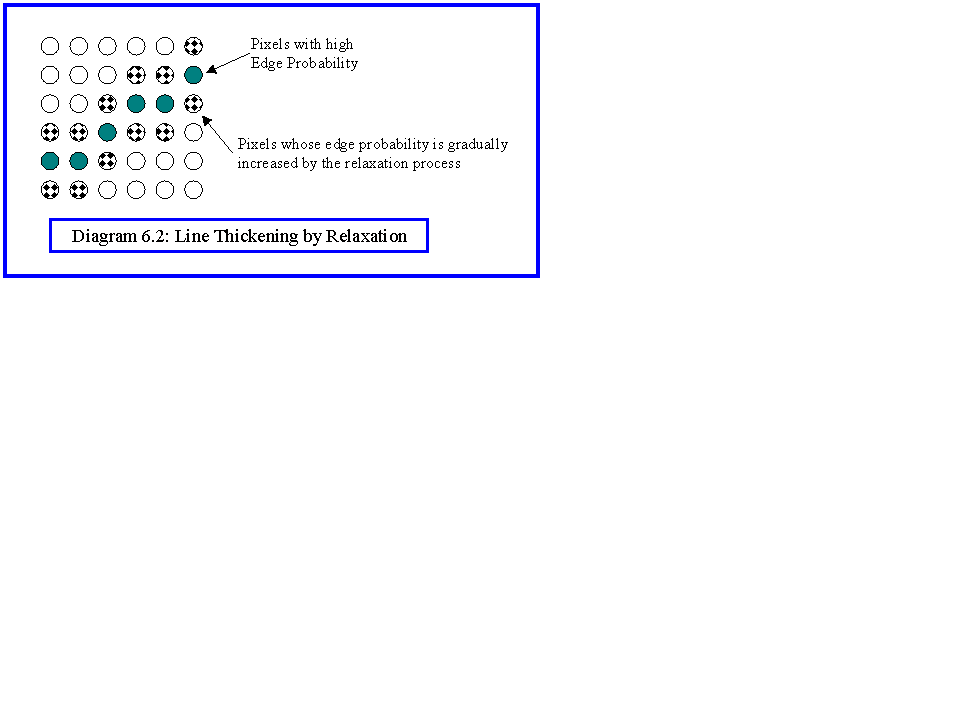
A second example is edge point detection. Diagram 6.1 shows symbolically the output of a simple edge detector. The problem that we are trying to solve is to make the relaxation process join up the contours, while making the isolated edge points disappear. This is not so easy, since relaxation processes tend to have side effects such as thickening lines (Diagram 6.2). A simple schema:
1. An initial estimate of the probability of a pixel being an edge can be derived from the edge point magnitude P1(ai:edge) = g(ai)/gmax
2. The compatability coefficients between two pixels can be derived from the edge directions:
r(ai:edge,aj:edge) = | 1 - |(q(ai) - q(aj)|/p |
which is a factor which varies between 0 and 1 depending on how closely the edge directions agree. In contrast to this, the other compatibility factors ( r(ai:notedge,aj:edge), r(ai:edge,aj:notedge), r(ai:notedge,aj:notedge) ) convey no information, and should be set to a neutral value say 0.5. Thus adjacent pixels are only considered edge points if their edge directions agree. A more complex scheme would be required to express the fact edge directions must be along a contour direction.
3. Pixels only influence their neighbours, so:
|
Cij = |
1 if ai next to aj |
|
= |
0 otherwise |
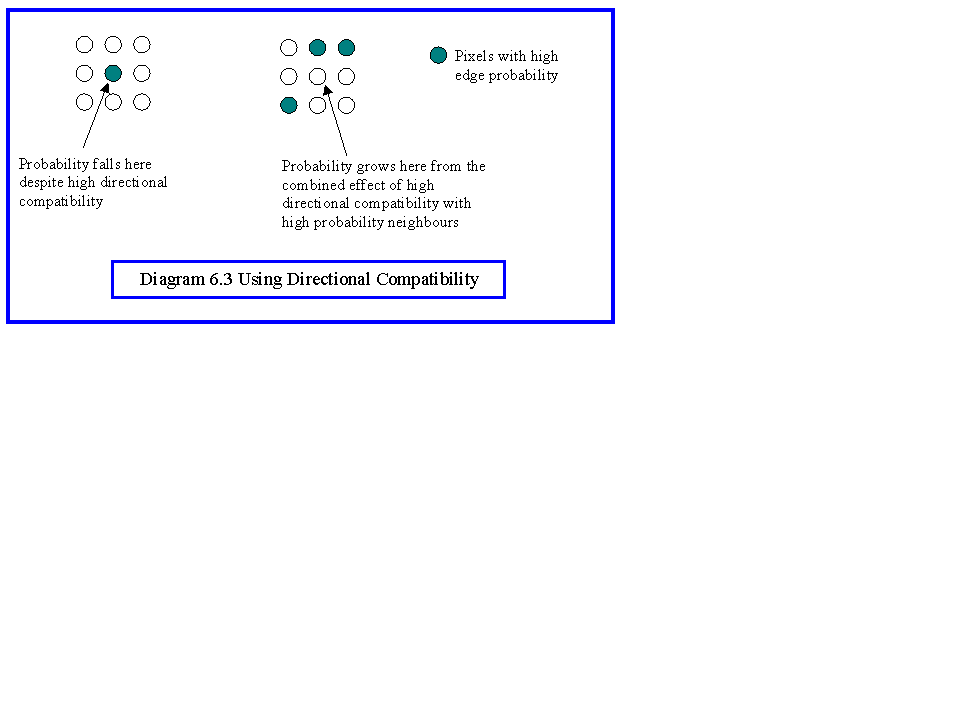
The behaviour of this scheme can be described by considering the particular case of the isolated edge shown in diagram 6.3. The fact that there are adjacent edge directions that agree is compensated by the fact that the probabilities of the adjacent points being edges is low. Hence, the probability of the isolated pixel being an edge is reduced. Note, importantly, that the probability of the adjacent pixels with compatible directions will be increased. For a pixel with neighbouring strong edges, the position is reversed. Two adjacent pixels have high edge probabilities, and have edge directions that agree. Thus the probability of the centre pixel being an edge is increased. There is also a decrease in the probability of the two adjacent pixels.
In summary, the algorithm strengthens existing probabilities where pixels belong to a contour, and weakens them where they do not. Thus, the pixels from the end of a contour can grow, and providing they join up with other contours soon enough, will eventually form edges. Isolated edge points weaken as their influence is spread by the iterations, and will eventually collapse without support.
Convergence
Authors have commonly observed one property of relaxation schemes, that after an initial improvement in a small number of iterations, the scheme collapses and produces an answer that is obviously eroneous. In the limit, there will be a trivial solution in which the probability of any particular label moves to zero or 1. Controlling this effect is yet another problem, whose solution is heuristic in nature, facing the programmer. In order to determine when the iteration has converged. Several consistency measures have been suggested, but the simplest is that:
" i,j Ps(ai:lj) = Qs(ai:lj)
It has not been possible to prove the convergence properties of equation 1, though, necessary (not sufficient) conditions have been found. In many practical cases convergence has been found to be slow. An heuristic approach to remedy this is to raise the right hand side to a power, w, which accelerates convergence by a linear factor w.
Another way of viewing convergence is to separate the right hand side of equation (1) into two components as follows:
Ps+1(ai:ll) = Ps(ai:ll) + aril
where:
|
m |
|||
|
ril = Ps(ai:ll) ( Qs(ai:ll) / { |
S |
Ps(ai:lk) Qs(ai:lk) } ) - Ps(ai:ll) |
(Eqn 2) |
|
k=1 |
Thus, when a=1, equation (2) becomes equivalent to equation (1). The process can now be regarded as an error correction, and convergence occurs when the error term r falls to zero. The constant a can now be chosen to optimise the speed of conversion. It can be regarded as a step size factor in the iterations.
Compatibility coefficients
Unfortunately, the formal mathematical treatment of the relaxation problem tells us very little about the important practical question of choosing the compatibility coeffiecients, r([ai:lj], [ak:ll]), or the blending coefficients Cij. However, it has enabled work to be done in identifying inherent bias in particular cases of relaxation algorithms. The choice of these constants, along with the step size, a, will have a profound influence upon the result to which the process converges, and success in applying relaxation techniques frequently depends on careful adjustment of these constants.
Simulated Annealing
A closely allied technique is simulated annealing, sometimes called stochastic relaxation. Here, the object is to introduce a random element into the iteration scheme, to prevent the result from becomming 'stuck' in a secondary maxima and never convergint to the true optimum. In essence, a random factor is added to equation 1 whose value is made to depend on a 'temperature'. As the temperature is increased, so larger disturbances are put into the system, when it is reduced, the convergence process takes place, and a result is sought.
Applications
Relaxation is an old technique, predating computer vision work, and has been used as the basis of iterative solutions of systems of equations, solving layout problems, breaking codes and many other applications. In computer vision it has been applied to:
Region based Segmentation
Edge point detection
Curved boundary extraction
Matching stereo pairs
Handwriting interpretation
etc
{kind=link}
{kind=link}
{kind=link}